Site Reliability Engineering (SRE) has become an essential part of modern software development and operations. As systems get advanced and user expectations for dependability rise, organizations must develop strong plans to guarantee their services remain available, performant, and resilient. This post examines 10 fundamental SRE best practices to help you design and manage dependable systems. Whether you're new to SRE or want to improve your current processes, these actionable insights can help you achieve operational excellence.
What is Site Reliability Engineering (SRE)?
Site Reliability Engineering (SRE) is a field that uses software engineering approaches to address infrastructure and operational issues. Google introduced SRE, which attempts to produce scalable and highly dependable software systems. The underlying principle of SRE is to approach operations as a software problem, utilizing coding, automation, and proactive tactics to address operational inefficiencies.
Key Principles of SRE
- Embracing Risk: Balancing system dependability and innovation through managed risk-taking for speedier development cycles.
- Service Level Objectives (SLOs):
- Establishing quantifiable objectives for reliability.
- To measure performance, use metrics such as Service Level Indicators (SLIs) and error budgets.
- Eliminating Toil
- Automating repetitious chores without long-term benefit.
- Allowing teams to focus on strategic improvements.
- Monitoring and Observability
- Obtaining detailed insights into system behaviour via logs, metrics, and traces.
- Providing actionable notifications to prevent "alert fatigue".
How SRE Differs from Traditional IT Operations
| Aspect | SRE | Traditional IT Operations |
|---|---|---|
| Focus | Proactive design and maintenance | Reactive issue resolution |
| Tools | Automation, observability platforms | Manual processes, monitoring tools |
| Involvement | Embedded in system architecture | Limited to operational roles |
Example:
In a usual IT environment, downtime can result in lengthy resolution periods while teams investigate and manually restore services. In contrast, SRE employs automated rollback techniques and predictive monitoring to proactively reduce downtime.
How Does SRE Integrate with DevOps?
SRE enhances DevOps by offering a prescriptive approach to dependability. DevOps emphasizes culture and teamwork, whereas SRE offers frameworks and tools for measuring dependability (SLOs, SLIs, and error budgets).
- Increase automation and decrease labour.
- Actively manage hazards in complicated systems.
Why SRE Is Important for Modern Software Systems
The complexity of modern software systems requires a systematic approach to dependability. Here's why SRE is necessary.
1. Managing Cloud-Native Complexity
Microservices, containerization, and distributed architectures have created challenging interdependencies to manage manually. SRE methods such as distributed tracing and centralized logging aid in maintaining visibility.
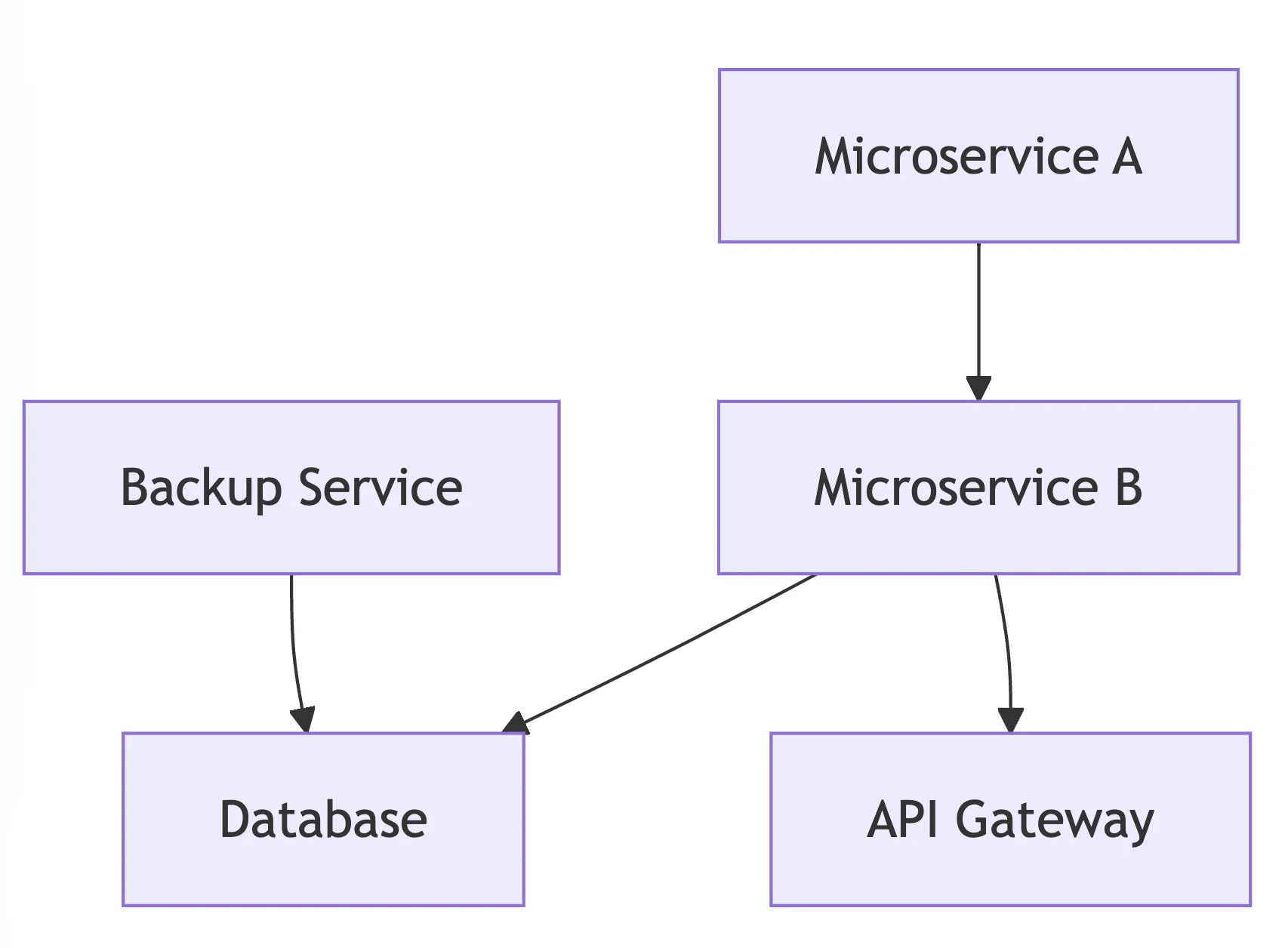
The above diagram demonstrates interconnections in a microservices architecture.
2. Meeting Customer Expectations
Customers expect services to be:
- Always available: Downtime during critical hours can result in user dissatisfaction.
- Performant: Slow response times directly affect user engagement and revenue.
3. Enabling Scalability with Automation
As systems grow, manual tasks become a bottleneck. Automation is essential for SRE since it enables self-healing processes.
- Automated incident response.
- Continuous deployment pipelines.
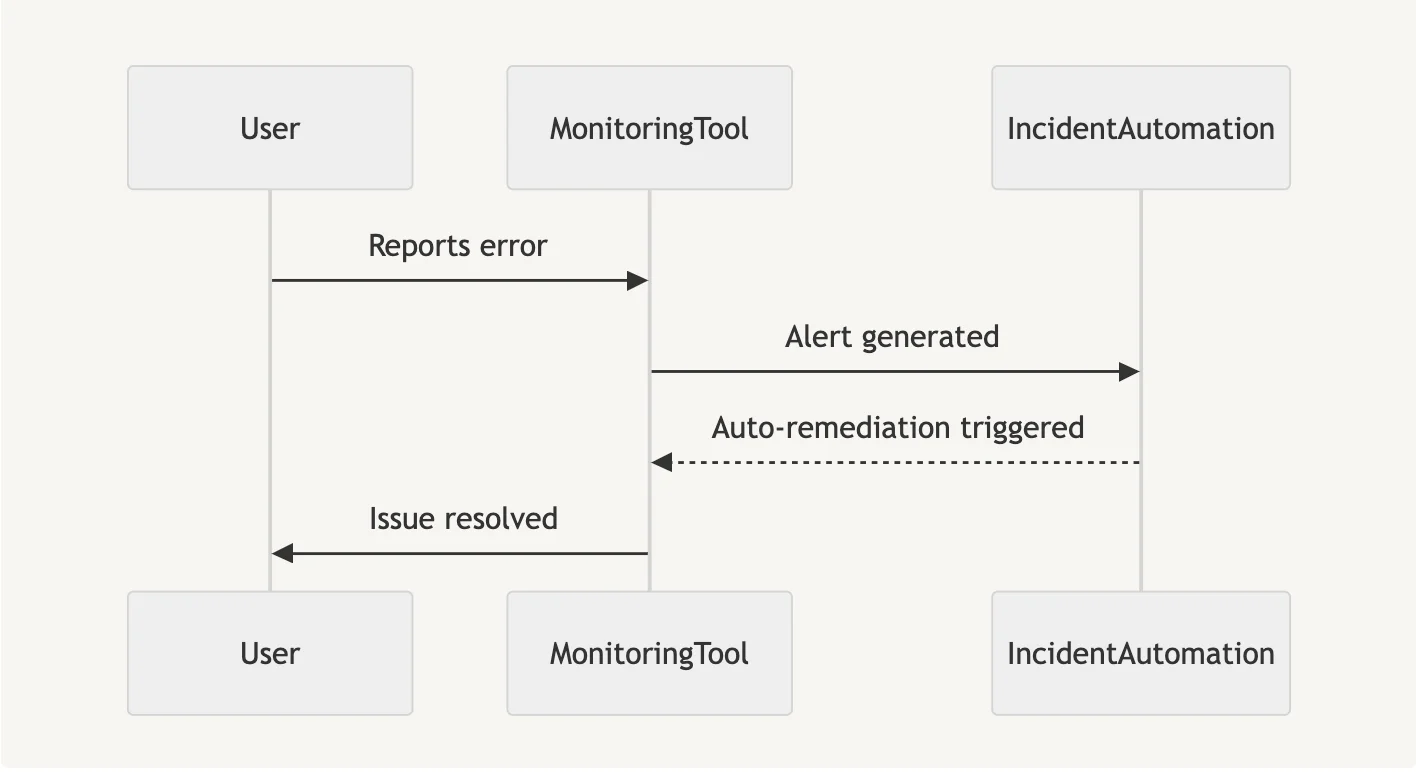
This sequence diagram illustrates an automated incident resolution process.
4. Protecting Revenue and Reputation
System dependability has a direct influence on a company's bottom line.
- Downtime costs: Revenue lost due to service outages.
- Reputation damage: Loss of client confidence due to recurrent disruptions.
Example: In 2023, a large financial services organization had a $10 million loss due to a 2-hour interruption. SRE approaches like as fault-tolerant design and chaotic engineering can help to reduce or eliminate such disruptions.
Let us now take a look at 10 Essential SRE Best Practices for Reliable Systems.
1. Establish and Measure Service Level Objectives (SLOs)
Service Level Objectives (SLOs) are important to SRE methods, serving as a common language for engineering teams and business stakeholders. They are measurable objectives for service dependability, allowing teams to focus on user-centric outcomes. A well-defined SLO may help drive prioritization, influence architectural decisions, and create team trust by setting clear expectations.
Steps to Set Effective SLOs:
- Identify Key User Journeys
- This includes identifying essential interactions that users experience with your service. For example, in an e-commerce platform, procedures like as product searches, adding products to the basket, and completing checkout are critical.
- Determine Metrics: Metrics should appropriately reflect user experiences, including:
- Availability: The percentage of time the service is available.
- Latency: Response time for critical transactions.
- Error Rate is the percentage of unsuccessful requests or activities.
- Durability: Storage services that maintain data integrity over time.
- Set Realistic Targets
- Targets must balance ambition with feasibility.
- For example, a startup with minimal resources may strive for 99.5% uptime, but a multinational corporation may aim for 99.99% or higher to fulfil severe SLAs.
- Regularly Review
- Users' requirements and company priorities shift over time.
- SLOs must be reviewed regularly to ensure they remain relevant.
- Tracking and Visualizing SLOs:
- Tools like SigNoz, Prometheus, Datadog, and Grafana let teams track metrics in real time.
- Create dynamic dashboards to show trends and notify on breaches. For example, a live SLO dashboard that displays rolling mistake rates over the previous 30 days might offer engineering teams relevant data.
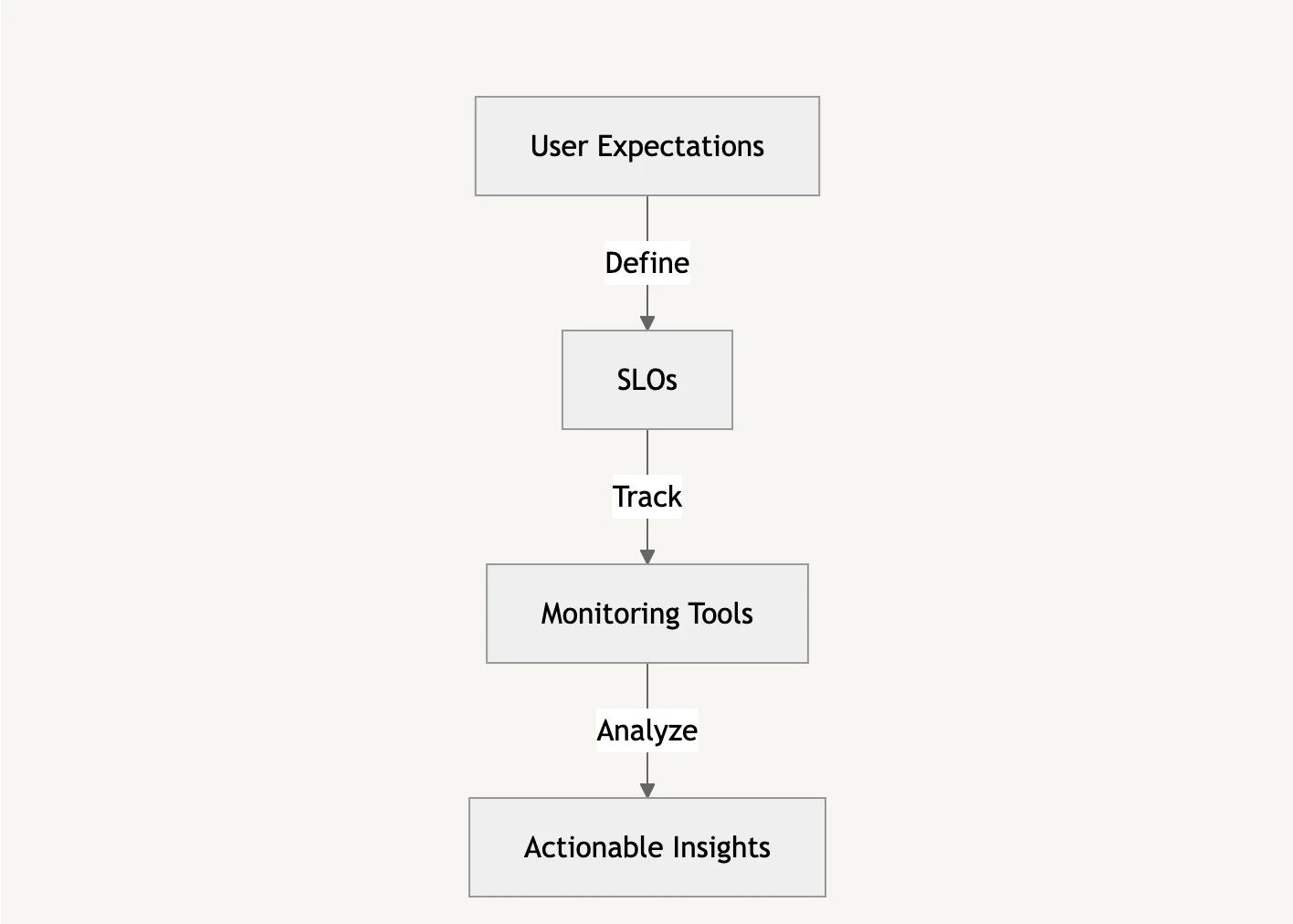
SLOs are not only technical measures; they have a direct influence on decision-making.
- Feature Rollouts: Before deploying new features, ensure that the error budgets (i.e., permitted unreliability) remain intact.
- Reliability vs. Innovation: Determine whether to repair current reliability gaps or incorporate new capabilities depending on SLO adherence.
- Incident Prioritization: Critical events that impact SLO performance require quick attention.
Example Use Case: Consider a video streaming service with an SLO demanding 95% of broadcasts to start within 3 seconds. Monitoring reveals a drop to 92% during peak hours, prompting an engineering effort to improve CDN setups, ensuring SLO is maintained and customer happiness is restored.
2. Implement Effective Incident Management Processes.
Incidents are unavoidable, but effective incident management techniques may mitigate their impact. A proactive approach offers faster outcomes decreases customer impact, and actionable learnings for the future.
Building a Comprehensive Incident Response Plan
- Define Severity Levels
- Establish severity levels based on impact.
- P0: Complete outage affecting all users.
- P1: Partial outage affecting critical features.
- P2: Minor issues with no user impact.
- Establish severity levels based on impact.
- Assign Clear Roles
- Incident Commander: Oversees the response, ensuring coordination.
- Scribe: Documents all actions taken during the incident.
- Subject Matter Experts (SMEs): Provide specialized technical expertise.
- Establish Communication Protocols
- Use tools like Slack, PagerDuty, or Microsoft Teams to centralize communication.
- Notify stakeholders (e.g., product managers, customer support) promptly via email or dashboards.
- Ensure 24/7 Coverage
- Create well-structured on-call schedules with fair rotation to avoid burnout.
Incident Response Workflow
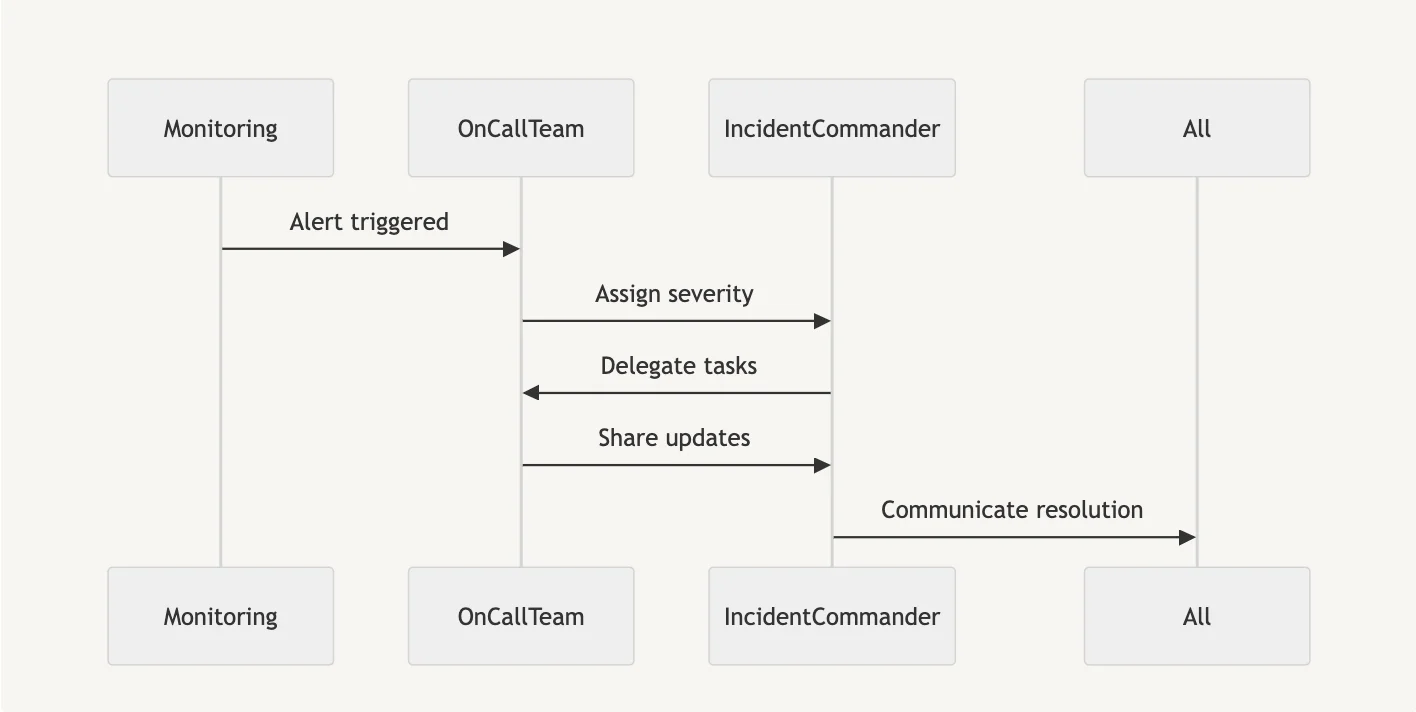
- Triage Efficiently: Quickly analyze the breadth and give severity.
- Centralized Communication: Use a single, dedicated channel for updates and cooperation.
- Document in Real Time: Maintain a thorough record of activities, hypotheses, and results.
Blameless Post-Incident Reviews
After the situation is resolved, perform a review to discover the root causes.
- Long-term preventative actions.
- Improving tools or procedures.
3. Automate Repetitive Tasks to Reduce Toil
Manual, repetitive activities cost valuable engineering time and cause operational inefficiencies. Toil, defined as manual, repetitive work with little long-term benefit, should be discovered and reduced in a methodical manner.
Identifying Toil
- Log Manual Efforts: Track recurring tasks such as patch updates, server restarts, or log reviews.
- Categorize Tasks: Divide work into high-value and low-value buckets to prioritize automation.
Strategies for Automation
| Task | Tool | Example |
|---|---|---|
| System Configuration | Ansible, Puppet | Automate VM or container setup |
| Deployment Processes | Jenkins, GitHub Actions | Automate CI/CD pipelines |
| Self-Healing Mechanisms | Kubernetes | Automatically restart unhealthy pods |
Examples of Self-Healing Systems:
- Auto-Scaling: Dynamically add and remove resources to meet workload needs.
- Service Restarts: Health probes will automatically restart failing processes.
- Rollbacks: If a deployment fails, automatically revert to a previous stable version.

- Automate routine processes, but need human participation for important situations like major incident escalation. Regularly assess automated systems to maintain effectiveness and alignment with growing corporate goals.
Result: Reduced toil allows engineers to focus on innovation and long-term dependability improvements.
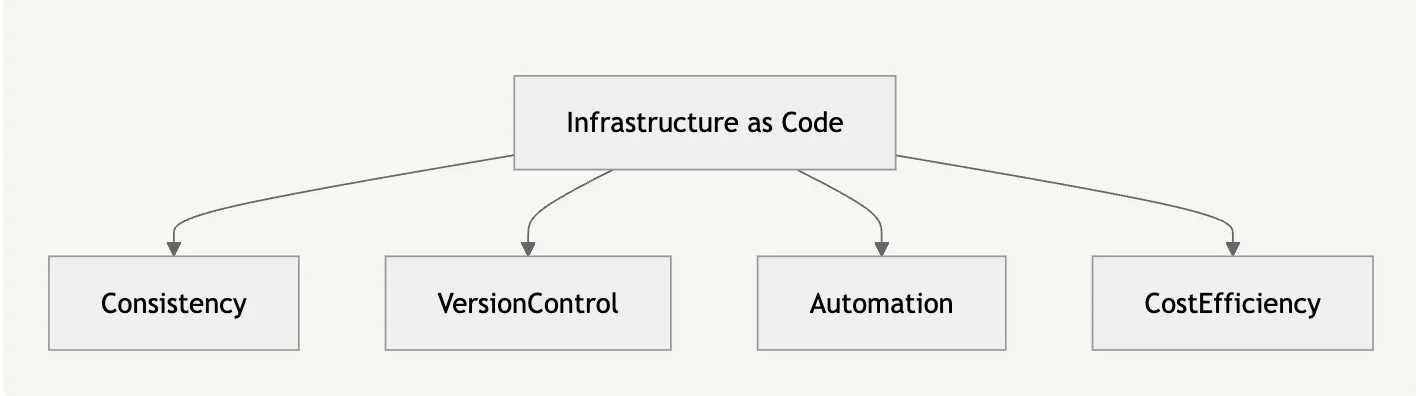
4. Implement Infrastructure as Code (IaC) practices.
Infrastructure as Code (IaC) transforms manual operations into automated workflows. IaC provides consistency, scalability, and traceability across environments.
Benefits of IaC
- Consistency: Using version-controlled infrastructure specifications prevents environment drift.
- Version Control: Track all infrastructure changes, allowing for rollbacks and cooperation.
- Automation: Easily interface with CI/CD workflows to accelerate deployments.
- Cost Efficiency: Easily scale infrastructure up or down based on demand, maximizing resource use.
Popular IaC Tools
| Tool | Key Features |
|---|---|
| Terraform | Cloud-agnostic, modular templates |
| AWS CloudFormation | AWS-specific templates |
| Ansible | Orchestration and configuration |
| ARM Templates | Azure-native declarative JSON templates |
| Bicep Files | Simplified syntax for authoring ARM templates |
Adopting IaC
- Start with a small and manageable application or service: Begin by selecting a simple, low-risk application or service to implement IaC practices. This allows your team to familiarize themselves with the tools and processes without significant impact on critical systems. For example, you might start with automating the infrastructure for a development or testing environment rather than production. This approach reduces complexity, accelerates learning, and provides quick wins to build confidence and refine workflows.
- Use Git or other version control systems for IaC templates: Store IaC templates in a version control system like Git to track changes, maintain history, and enable collaboration. This ensures transparency and provides an audit trail for all infrastructure modifications.
- Implement peer code reviews to ensure quality: Have team members review IaC templates to identify potential errors, enforce standards, and share knowledge. This practice improves quality, fosters collaboration, and helps prevent misconfigurations.
- Create modular reusable components to improve efficiency and scalability: Design IaC templates with modularity in mind. Reusable components (such as network configurations or storage modules) simplify scaling and maintain consistency across multiple projects.
Infrastructure Testing
- Validate infrastructure setups using tools such as Terratest and InSpec.
- Create disposable environments to test changes without interrupting production: Use Infrastructure as Code (IaC) tools to automate the creation of isolated testing environments that mirror production. For instance:
- Use Terraform or CloudFormation to define a staging environment with identical configurations to production.
- Deploy and test your changes in this environment using CI/CD pipelines. This can include functional, performance, or security tests.
- After testing is complete, destroy the environment automatically to minimize costs or clean up scripts in your pipeline.
5: Implement Gradual and Controlled Rollouts
Gradual rollouts allow teams to release upgrades in phases rather than all at once. This decreases the likelihood of widespread failures and provides time to evaluate modifications in a controlled setting.
Techniques for Progressive Delivery:
- Canary Releases
- Updates are initially given out to a limited number of users or servers, serving as a "canary in a coal mine" for detecting possible problems.
- For example, an e-commerce website can test a new payment method with 5% of users to assess success and problems before growing.
2. Blue-Green Deployments: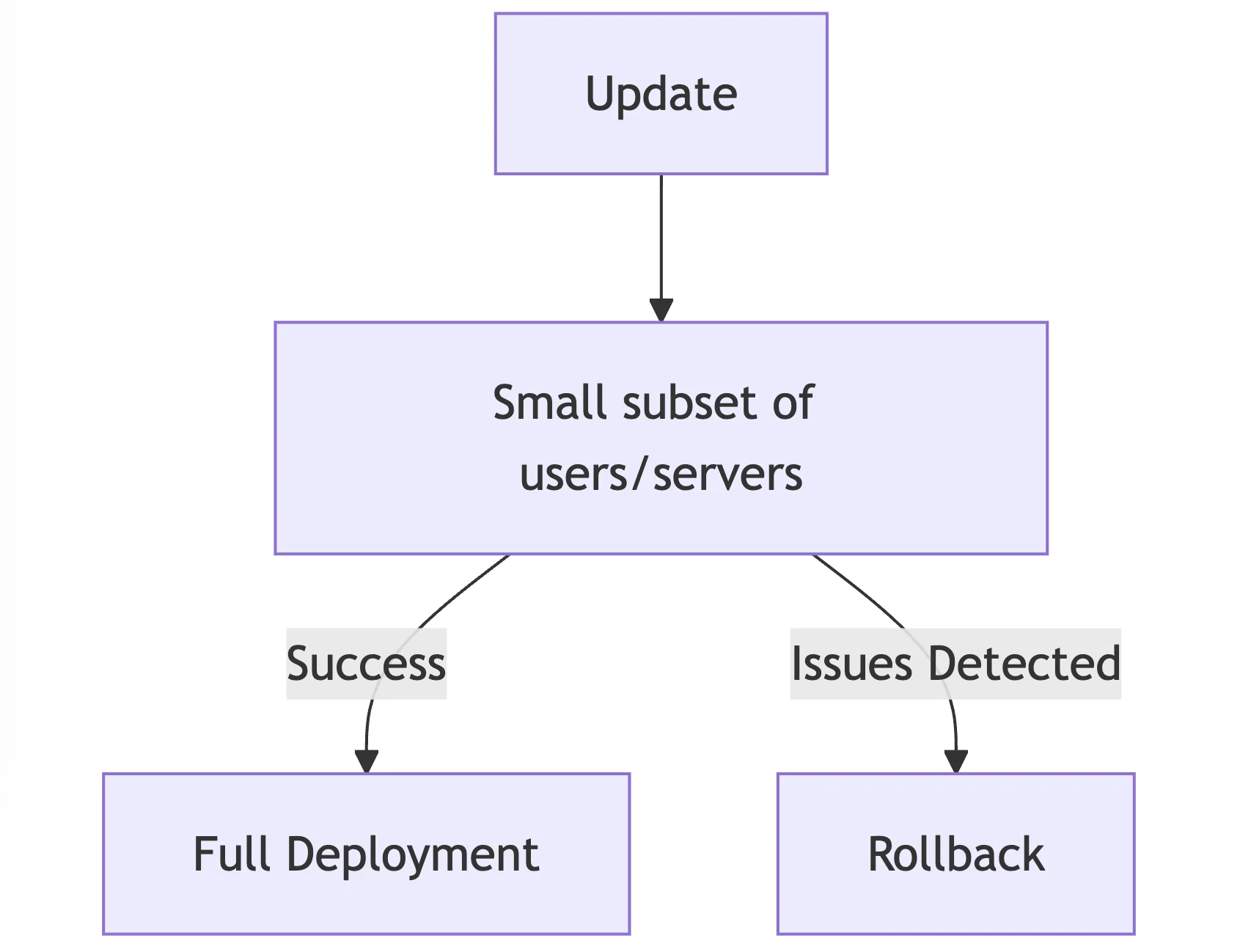
- Two identical production environments, blue and green, are maintained. Blue represents the current version, while green represents the upgrade.
- For example, after certifying the update in green, all user traffic is converted from blue to green, guaranteeing a smooth transition with no downtime.
3. Feature Flags: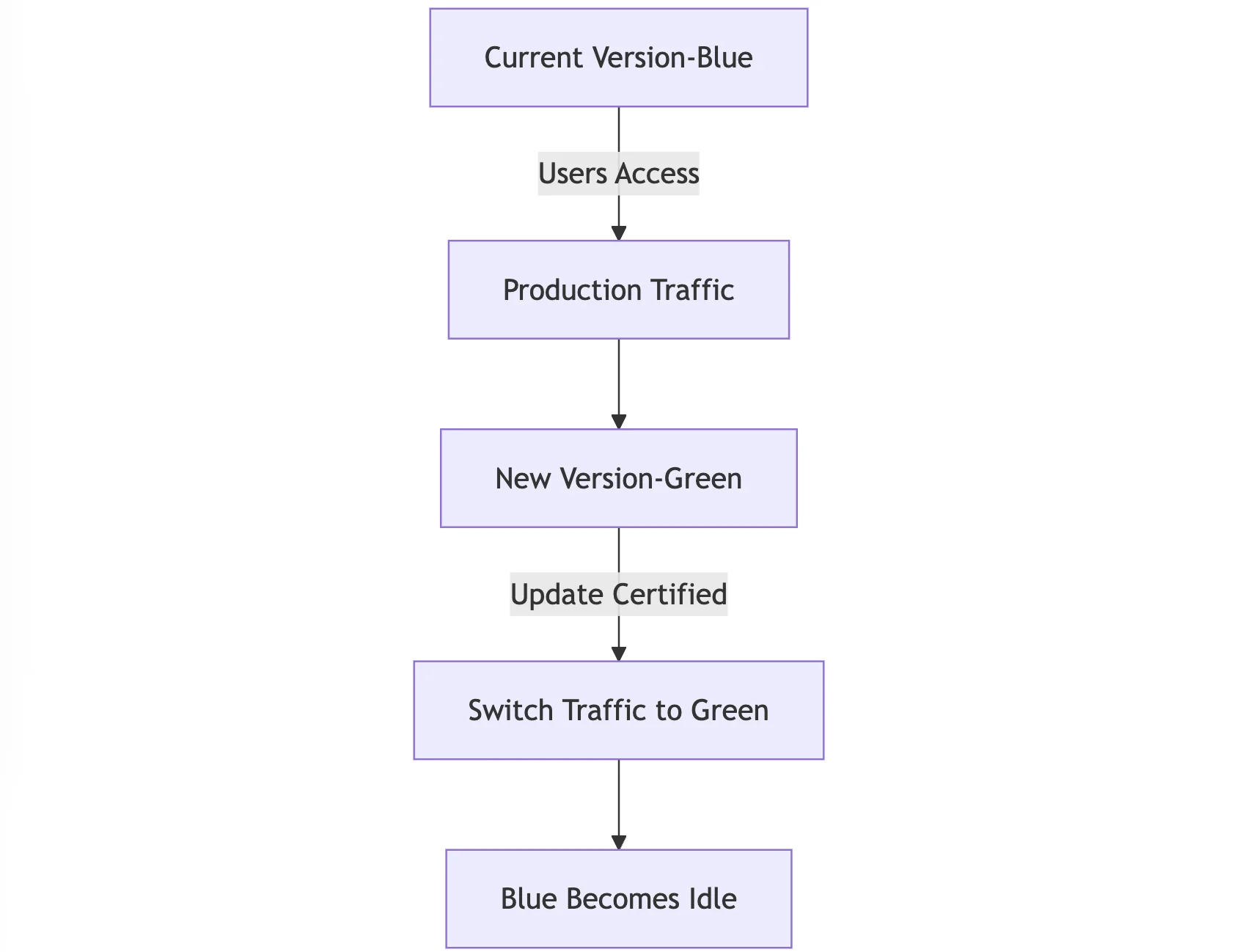
- Enable or disable features for certain users or groups without deploying additional code.
- For example, a streaming platform might utilize feature flags to launch a new recommendation algorithm exclusively for premium customers, gradually expanding it depending on feedback.
### Best Practices for Rollout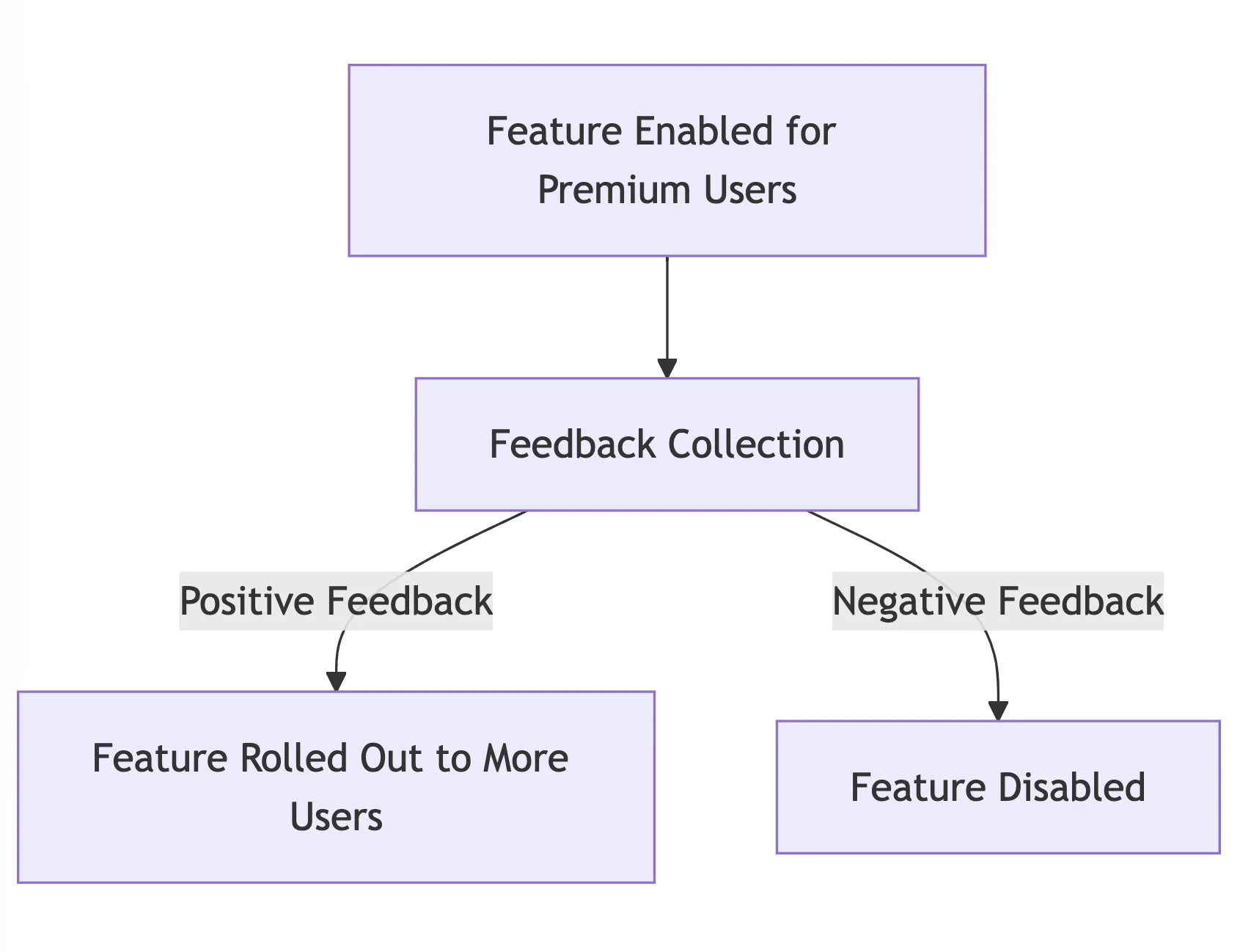
- Define Clear Metrics: Determine what "success" entails—low mistake rates, great user happiness, or consistent performance. Some of the key metrics can be:
- Error rates (e.g., a 1% error threshold might trigger a rollback).
- Response times (e.g., if the average response time exceeds 2 seconds for more than 10% of requests, trigger a rollback).
- User satisfaction (e.g., user complaints or negative feedback surpassing a predefined number).
- Automated Rollbacks: Configure systems to revert changes automatically if mistakes exceed a certain level. The threshold can be defined using:
- Error rates: For instance, if the error rate exceeds 5% over a 10-minute window, the system can trigger an automatic rollback.
- Performance degradation: If performance metrics (e.g., CPU usage or latency) degrade past a specific threshold, roll back to the previous stable state.
- Business KPIs: If specific KPIs (e.g., conversion rates, revenue) drop below a defined threshold within a specified timeframe, initiate the rollback process.
- User feedback: Encourage early adopters to identify the pain points for the mass deployment. Collect user feedback based on the following:
- Surveys: Immediate post-deployment surveys will be used to gauge user sentiment.
Feature Flags in Action:
- Separate when a feature is delivered from when it is made available to consumers, resulting in faster, safer updates.
- A/B testing using feature flags involves comparing two variants of a feature to see which works better.
- For example, a food delivery service may compare two UI designs for placing an order and gather data to decide which is more effective.
Monitoring during rollouts
Use tools such as SigNoz to compare performance metrics between previous and new releases. Using visual dashboards, you can monitor latency, error rates, and user engagement simultaneously.
Preparing for Rollbacks:
- Test rollback processes before deployments.
- Automate the rollback method to reduce delays if problems occur.
Example: A new search function introduced by an online shop is instantly rolled back if search latency exceeds 2 seconds.
6. Design for failure and embrace chaos engineering.
In distributed systems, failures are unavoidable. Designing for failure guarantees that systems function even when something goes wrong.
Designing for Failure Principles

- Maintain backup components to guarantee availability.
- For example, an online bank replicates user data across different areas, ensuring that even if one fails, it is still available from the others.
- Circuit Breakers:
- Stop forwarding requests to failing services to avoid further pressure.
- For example, if a payment gateway fails, orders can be deferred to avoid overloading the system with retries.
- Graceful Degradation:
- When system components fail, ensuring essential functionality remains operational.
- Example: A streaming service might have a lower video quality when bandwidth is low, rather than stopping playback entirely.
- Retry Mechanisms with Backoff:
- To avoid overloading services, retries should be made at increasing intervals (backoff).
- For example, a messaging app will retry to deliver a message after 2 seconds, 4 seconds, and so on to avoid flooding the server.
What is chaos engineering?
Chaos engineering investigates how systems react under failure. Instead of waiting for issues, failures are deliberately generated to expose flaws.
Steps for Starting Chaos Engineering:
- Determine usual system behaviour (for example, average response times).
- Develop theories about how the system should respond to failures.
- Test failures such as excessive latency or node crashes in a controlled environment.
- Analyze the data to identify and resolve weaknesses.
Real-World Example: Netflix's Chaos Monkey randomly shuts down production servers to enhance resilience against unexpected failures.
Disaster Simulations: Regularly conduct "game days" where teams look into the failures (like database crashes) to practice recovery strategies and find gaps in preparedness.
7. Establish a Culture of Blameless Postmortems
When an incident occurs, the focus should be on determining what went wrong and how to avoid it, rather than assigning blame. Blameless postmortems provide an environment in which teams feel comfortable discussing concerns freely.
Steps for a Blameless Postmortem:
- Establish a Safe Environment:
- Promote openness without fear of penalty.
- For example, a team member acknowledges that they pushed defective code without considering the consequences.
- Focus on Events, Not People:
- Analyze decisions and their context, rather than assigning fault.
- For example, "The system allowed deployment without enough tests" rather than "X forgot to test the code."
- Identify Contributing Factors:
- Consider systemic concerns such as lack of automation, confusing processes, and tool restrictions.
- Define Actionable Items:
- Provide specific recommendations to prevent future occurrences.
- For example, add automated tests for edge cases causing issues.
Key Elements
- Timeline: Recount the events leading up to and during the occurrence.
- Impact: Determine how users or services were affected.
- Root reason: Determine the underlying technical or procedural reason.
- Action Items: Create a clear improvement plan.
Outcome: Sharing postmortem insights across teams minimizes the probability of repeating mistakes, enhances procedures, and fosters trust.
8. Implement Comprehensive Monitoring and Observability
Observability refers to the ability to comprehend why something is occurring in your system, whereas monitoring focuses on identifying issues. Both are necessary for sustaining dependability.
Key Observability Components
- Metrics:
- Numerical data representing system performance, such as server CPU usage or API response times.
- Logs:
- Detailed event records, useful for debugging issues.
- Traces:
- Tracks the journey of a request across services in a distributed system.
Building an Observability Stack
- Distributed Tracing: Tools like SigNoz visualize how requests flow via microservices, assisting in identifying delays or bottlenecks.
- Log Aggregation: Use centralized tools to organize and analyze logs from various components.
- Real-Time Dashboards: Numerous tools and platforms provide live metrics to enable speedy decision-making.
Actionable Alerts
- Set Meaningful Alerts: Only notify on serious concerns, such as an API response time of more than 500ms.
- Reduced Alert Noise: To prevent on-call engineers from being overwhelmed, group related warnings and prioritize them by severity.
- SLO-Based Alerts: Tie alerts to service level goals (SLOs) to ensure they are relevant to users.
Example: A SaaS firm sets an alert for login failures that surpass 1% of total traffic, initiating an inquiry before consumers see widespread problems.
Using SigNoz to Enhance Observability
SigNoz is an open-source observability platform that aims to simplify and improve SRE techniques. It provides a comprehensive picture of system performance by combining distributed tracing, metrics monitoring, log management, and custom dashboards on a single platform.
Benefits of Using SigNoz
- Distributed Tracing:
- Identify bottlenecks in your system by seeing how requests flow across microservices.
- For example, identify a single microservice that slows down the checkout process in an e-commerce application.
- Metrics Monitoring:
- Real-time monitoring of important performance metrics such as CPU, memory, and request latencies.
- Log Management:
- Centralize and analyze logs for efficient debugging and issue resolution.
- Custom Dashboards:
- Create dashboards that measure crucial indicators and correspond with your service level goals (SLOs).
Getting Started with SigNoz
- Install SigNoz.
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account and get 30 days of unlimited access to all features.

You can also install and self-host SigNoz yourself since it is open-source. With 19,000+ GitHub stars, open-source SigNoz is loved by developers. Find the instructions to self-host SigNoz.
- Instrument Your Applications:
- Add OpenTelemetry SDK to your codebase for easy data collecting.
- Configure Data Sources:
- Identify problems in your system by seeing how requests flow across microservices.
- For example, identify a single microservice that slows down the checkout process in an e-commerce application.
- Metrics Monitoring:
- Real-time monitoring of important performance metrics such as CPU, memory, and request latencies.
- Log Management:
- Centralize and analyze logs for efficient debugging and issue resolution.
- Custom Dashboards:
- Create dashboards that measure crucial indicators and correspond with your service level goals (SLOs).
How SigNoz Enhances SRE Practices
- Streamlined Troubleshooting: Unified data sources make it easier to correlate metrics, traces, and logs, resulting in speedier troubleshooting.
- Proactive Insights: Detect performance irregularities before they turn into problems.
- Cost-Effective Scaling: Monitor resource utilization and adapt capacity plans based on dashboard data.
Example Use Case: A SaaS firm utilizes SigNoz to track API response times and database queries. When response times surpass criteria, developers can rapidly determine if the problem is in the code, the infrastructure, or the external dependencies.
9. Encourage collaboration between development and operations.
Effective Site Reliability Engineering relies on collaboration between development and operations teams. Breaking down conventional silos fosters a culture of shared accountability and better communication.
Strategies to Promote Collaboration
- Shared On-Call Rotations: Developers and operations engineers share on-call duties for analyzing system behaviour during issues.
- Collaborative Design Reviews: Address operational problems (e.g., scalability, monitoring) during early feature development.
- Joint Postmortems: Conduct postmortems as a team to uncover systemic issues and potential fixes.
- Cross-Functional Teams: Form teams with individuals from both disciplines to tackle high-priority initiatives such as platform migrations and capacity optimization.
Promote Knowledge Sharing
- Organize tech talks or lunch-and-learns to address system issues and solutions.
- Use pair programming to foster trust and understanding among teams.
- Rotate team members between development and operations to gain practical expertise in both positions.
Aligned Incentives for Reliability
- Shared Metrics: Assess team performance using dependability indicators like as uptime, error rates, and SLO adherence. Developers and operations engineers share on-call duties for analyzing system behaviour during issues.
- Collaborative Design Reviews: Address operational problems (e.g., scalability, monitoring) during early feature development.
- Joint Postmortems: Conduct postmortems as a team to uncover systemic issues and potential fixes.
- Cross-Functional Teams: Form teams with individuals from both disciplines to tackle high-priority initiatives such as platform migrations and capacity optimization.
10. Continuously Optimize Capacity Planning
Capacity planning guarantees that your systems can effectively manage current demands while also growing for future development. Without it, you risk over-provisioning (and incurring extra expenditures) or under-provisioning (resulting in poor performance and downtime).
Key Aspects of Capacity Planning:
- Forecasting Resource Needs:
- Use previous data to estimate future requirements.
- For example, use seasonal traffic trends to plan for Christmas sales on an e-commerce site.
- Implement Auto-Scaling:
- Automatically adjust resources based on real-time requirements.
- For example, scale servers up for a product launch and down during off-peak hours.
- Optimize Resource Utilization:
- Reallocate unused resources to vital services.
- Regularly Review Plans:
- Adjust predictions weekly and quarterly to reflect new data and growth patterns.
Techniques for Capacity Planning
- Historical Analysis:
- Research historical use trends to predict future demands.
- For example, a video streaming business predicts increased demand on weekend evenings.
- Machine Learning Models:
- Apply ML algorithms to properly estimate resource demands, taking into account complicated factors.
- Scenario Simulations:
- Run simulations to prepare for unforeseen surges or breakdowns.
- For example, a ticketing platform replicates traffic during a huge concert sale.
To balance cost and performance, use cost management tools like AWS Cost Explorer and Google Cloud Cost Management to identify inefficiencies.
- Spot Instances: Use spot instances for non-critical tasks to save money.
- Serverless Architectures: Use serverless computing to handle unexpected workloads and pay only for what you need.
Regular Capacity Reviews
- Monthly Review: Compare actual usage against projections to discover inconsistencies.
- Quarterly Planning: Modify plans to accommodate impending events or new features.
- Annual Audits: Assess overall infrastructure efficiency to ensure alignment with long-term company objectives.
Example: A media platform uses auto-scaling to handle peak traffic during live events, therefore saving money during off-peak hours while preserving dependability.
Summary Table: 10 Best Practices in SRE
| Practice | Key Focus Areas |
|---|---|
| 1. Establish and Measure SLOs | Define realistic SLOs, track progress, and use them to guide engineering priorities. |
| 2. Effective Incident Management | Create response plans, define roles, establish communication channels, and conduct post-incident reviews. |
| 3. Automate Repetitive Tasks | Reduce toil, automate common tasks, implement self-healing systems, and balance automation. |
| 4. Adopt Infrastructure as Code (IaC) | Treat infrastructure as code, manage with version control, and validate changes with testing. |
| 5. Controlled Rollouts | Use canary releases, blue-green deployments, feature flags, and monitoring to ensure smooth rollouts. |
| 6. Design for Failure and Chaos Engineering | Implement redundancy, graceful degradation, chaos engineering, and disaster simulations. |
| 7. Blameless Postmortems | Focus on root causes, create psychological safety, and extract actionable insights from failures. |
| 8. Monitoring and Observability | Measure key metrics, implement tracing/log aggregation, and leverage tools like SigNoz for visibility. |
| 9. Foster DevOps Collaboration | Break silos, align incentives, and encourage shared reliability responsibility between teams. |
| 10. Optimize Capacity Planning | Forecast resource needs, use auto-scaling, balance costs, and review capacity regularly. |

Key takeaways
- SRE best practices provide a systematic approach to developing and sustaining trustworthy systems.
- Establishing explicit SLOs and adopting incident management are critical to guaranteeing reliability.
- Using automation and Infrastructure as Code reduces toil while improving operational consistency.
- Techniques such as incremental rollouts and chaotic engineering enable systems to gracefully tolerate faults.
- A culture of blameless postmortems and cooperation between development and operations promotes ongoing progress.
- Tools such as SigNoz give actionable information on system performance and behaviour.
- Regular Reviews and Auto-Scaling Strategies ensure systems meet demands efficiently while optimising the costs.
FAQs
What skills are needed to become an SRE?
To succeed as an SRE, you need a combination of technical and interpersonal abilities, including:
- Technical Skills:
- Include programming and scripting (e.g., Python, Go, and Bash).
- Linux/Unix system administration.
- network and cloud platforms (AWS, GCP, Azure)
- Frameworks for observing and monitoring
- Automation and Infrastructure as Code (e.g., Terraform and Ansible)
- Incident management and performance modification.
- Soft Skills:
- Clear communication and teamwork
- Problem-solving and critical thinking
- Capability to manage high-pressure circumstances.
How does SRE differ from traditional IT operations?
SRE has a fundamentally different strategy than standard IT operations:
- Proactive Design: Concentrates on incorporating dependability into the system rather than responding to problems.
- Engineering-Driven Solutions: Utilizes software development approaches to tackle operational issues.
- Automation First: Automates repetitive operations to decrease manual labour and improve efficiency.
- Data-Driven Metrics: Uses metrics such as SLOs and error budgets to assess and enhance dependability.
- Shared Responsibility: Bridging the gap between the development and operational teams.
- Resilience Over Perfection: Create systems that anticipate and recover from failures.
Can SRE practices be applied to small organizations?
Yes, SRE principles are scalable and may be used to smaller teams and businesses. Here's how.
- Prioritize identifying necessary SLOs for important services.
- Begin with simple monitoring and alerting technologies.
- Use Infrastructure as Code to maintain consistency.
- Save time by automating high-impact manual chores.
- Conduct blameless postmortems to identify and correct problems.
- As your team grows, progressively implement advanced approaches such as chaos engineering.
Small businesses can use a lightweight version of SRE to increase reliability without having a committed team.
What are some common challenges in implementing SRE?
Adopting SRE has its own set of challenges:
- culture Resistance: Moving from traditional operations to an SRE model frequently necessitates a considerable cultural transformation.
- Skill Gaps: Finding experts who are knowledgeable in both software engineering and systems operations might be tough.
- Complex Toolchains: Small teams may find it difficult to manage the numerous monitoring, automation, and observability tools available.
- Balancing Priorities: Convincing stakeholders to prioritize dependability above feature development is frequently difficult.
- Defining SLOs: Establishing meaningful and attainable SLOs needs iteration and cooperation.
- Managing Toil: Reducing repetitious manual work is a continual process that needs continuous review.
- Scaling Practices: Adjusting SRE methodologies to accommodate organizational growth and complexity is a challenging process.
To address these challenges, firms must invest in education, leadership buy-in, and tailored solutions that fit their unique needs.
