Unified observability transforms how organizations monitor and manage their IT infrastructure. With the increase in complexity of IT environments, traditional monitoring approaches fall short. Unified observability provides a comprehensive solution by integrating data from various sources into a single platform. This approach gives a holistic view of the entire IT ecosystem, enabling faster problem resolution and proactive issue prevention.
In this blog let’s dive into the concept of Unified Observability, uncovering how it has evolved from traditional monitoring to meet the demands of today’s IT environments.
What is Unified Observability?
Unified observability gives a unified view of IT infrastructure, applications, and security. It combines metrics, logs, and traces into a single platform for comprehensive insights. Unlike traditional monitoring, it integrates data from multiple sources, allowing teams to identify and resolve issues more efficiently.
Key components include:
- Metrics: Tracks resource usage (CPU, memory, network).
- Logs: Captures event data from systems and applications.
- Traces: Follows requests across application components.
It differs from traditional monitoring as it provides a holistic, integrated approach. Technologies such as AI, machine learning, and automation are used to detect patterns and anomalies, and trigger responses automatically. For instance, AI can predict a potential spike in traffic based on historical data trends, while automation handles the response, such as scaling resources to manage the increased load effectively.
Key benefits include:
- Faster troubleshooting: Teams can quickly trace the root cause of problems.
- Improved performance: Continuous optimization of systems is easier with a consolidated view.
- Enhanced security: Faster detection and response to threats across the entire system.
The Evolution of IT Monitoring
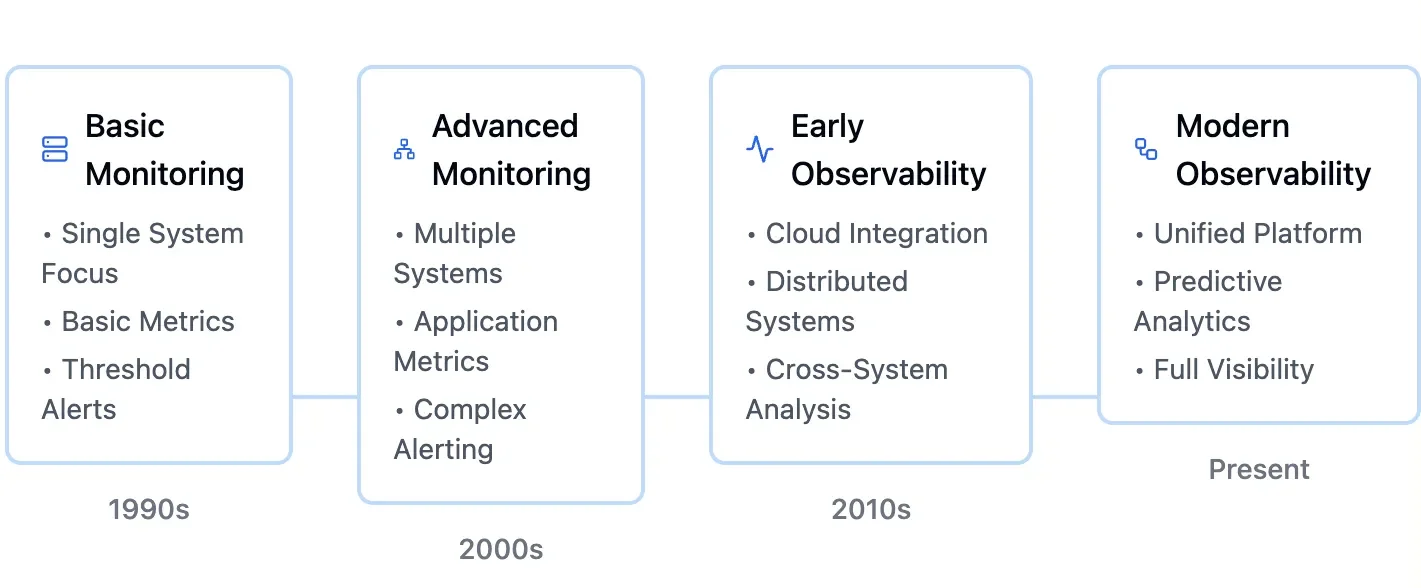
The growing complexity of systems—particularly with cloud-native applications and microservices—led to the emergence of observability. This approach extends beyond basic monitoring by analyzing logs, metrics, and traces together, enabling more efficient issue detection and resolution.
The transition to integrated observability platforms stemmed from the need for real-time visibility across diverse systems. By combining multiple data sources, these platforms enhance decision-making capabilities. For example, when API responses slow down in a microservices environment, teams can correlate metrics to identify whether the root cause lies in the database or network.
The rise of cloud computing and microservices created new monitoring challenges that traditional tools couldn't address due to these environments' dynamic, distributed nature. In response, observability platforms evolved to provide comprehensive visibility into distributed systems while offering predictive insights for maintaining performance and reliability.
Why Unified Observability Matters in Modern IT Environments
Modern IT ecosystems are intricate webs of interconnected services, applications, and infrastructure. There are various complexity concerns created due to this which are as follows:
- Difficulty in determining the root cause of issues
- Increased mean time to resolution (MTTR)
- Lack of visibility into system dependencies
- Siloed teams and tools
These challenges can be addressed by Unified observability as follows:
Addressing the challenges of complex ecosystems
Modern applications are dependent on multiple services and platforms, which can create blind spots in traditional monitoring tools. Unified observability helps in breaking down silos by gathering data from various sources such as logs, metrics, and traces. This unified approach ensures that potential issues are captured across all layers of the application stack, providing a clear view of system health.
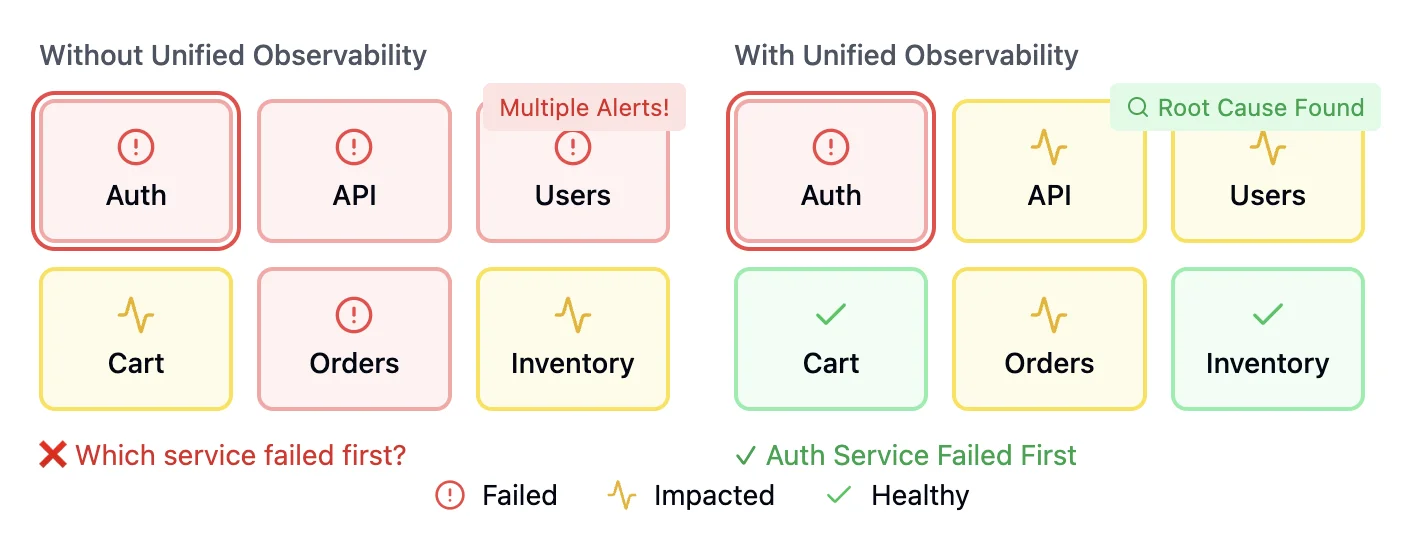
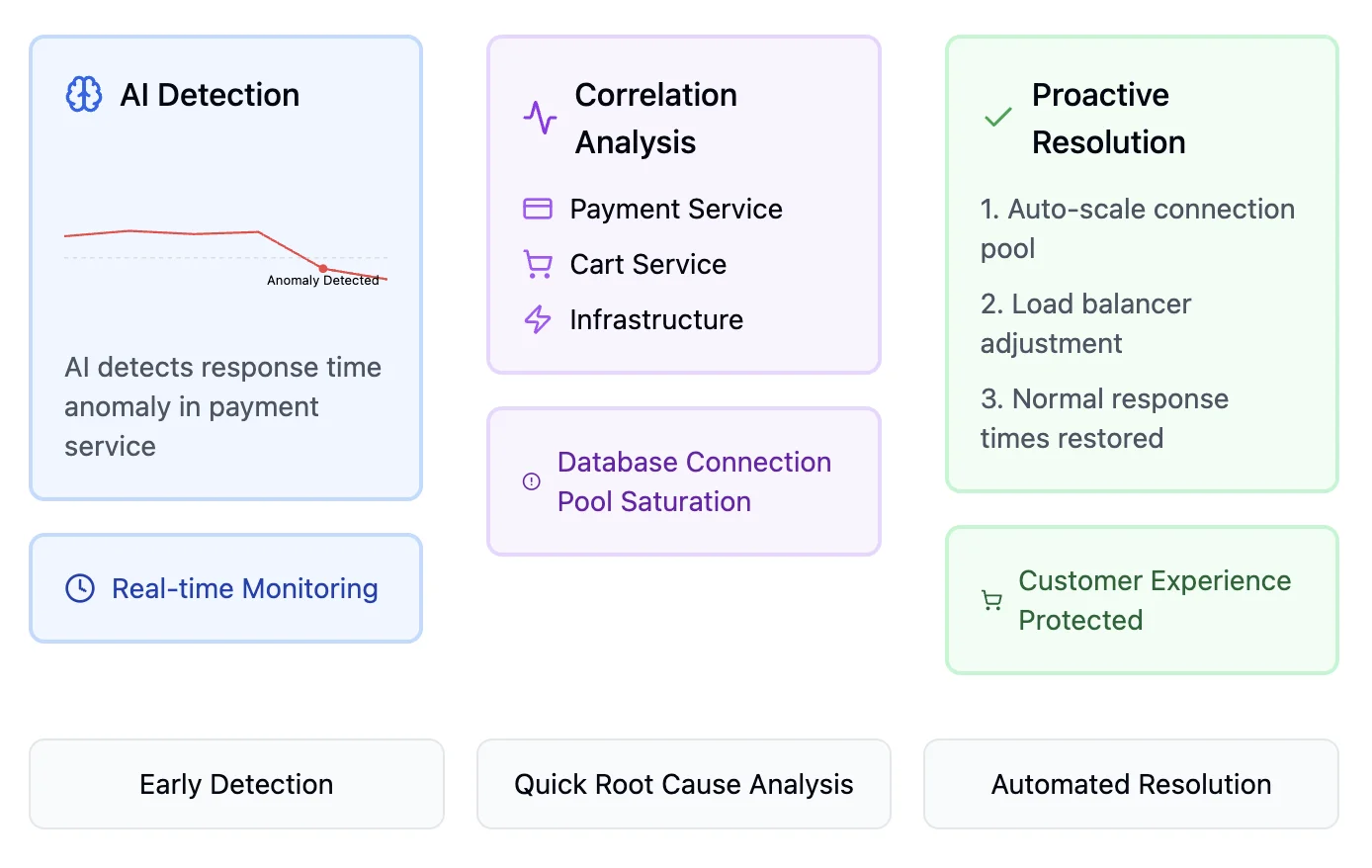
Proactive issue detection and faster problem resolution
Unified observability tools use Artificial Intelligence(AI) and machine learning to identify anomalies in real time. By correlating data across multiple layers—application, network, and infrastructure—teams can detect potential problems before they escalate into critical issues. This proactive approach reduces downtime and ensures smoother operations.
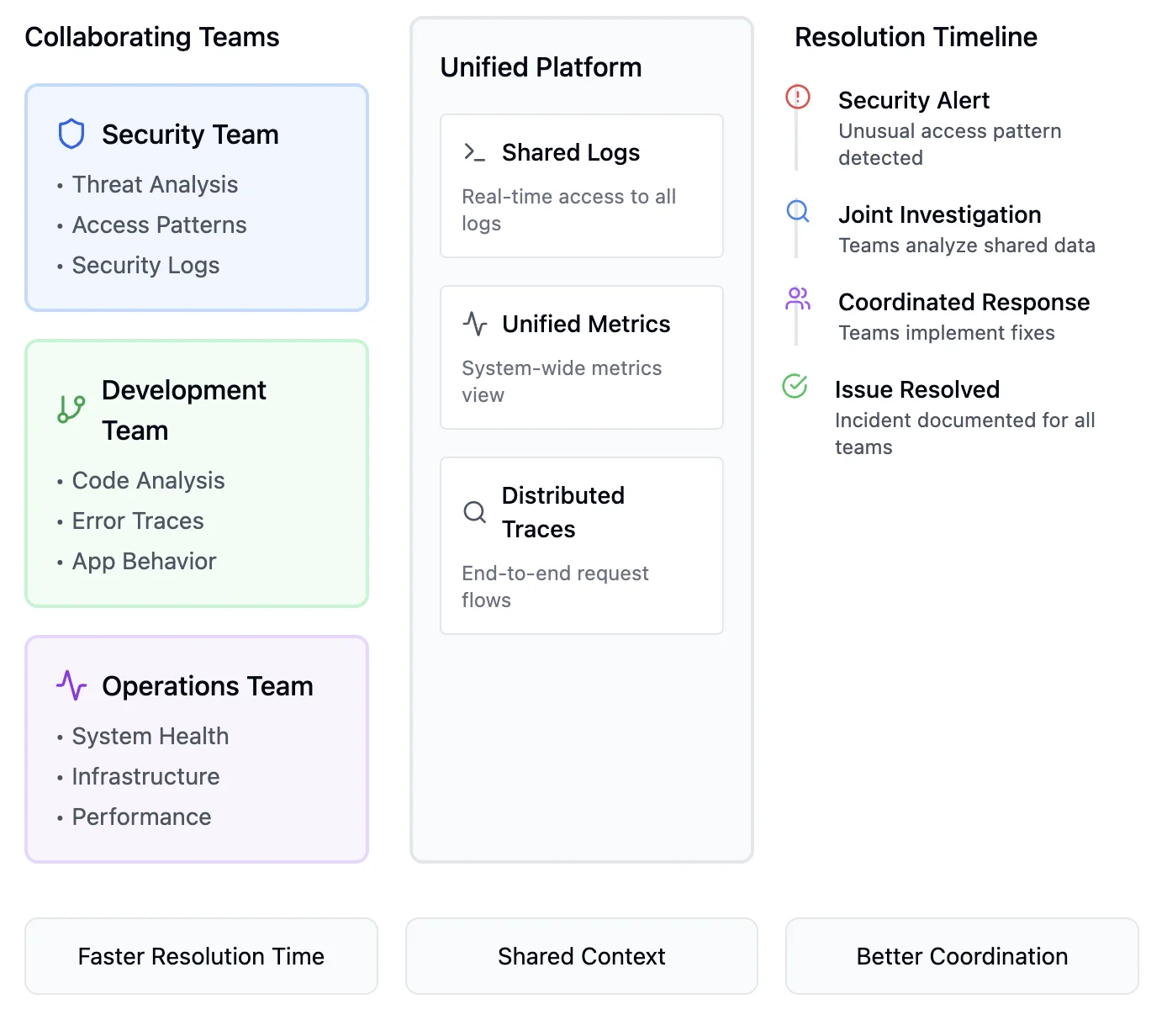
Improved collaboration between teams
Observability bridges the gap between development, operations, and security teams as it provides a common platform for data analysis. Teams can work together more efficiently. This shared context enables faster decision-making and more effective troubleshooting.
Enhancing system reliability and performance
Unified observability leads to improved system reliability by continuously monitoring system performance and identifying bottlenecks. Over time, insights from observability data can be used to optimize system performance and improve resource allocation.
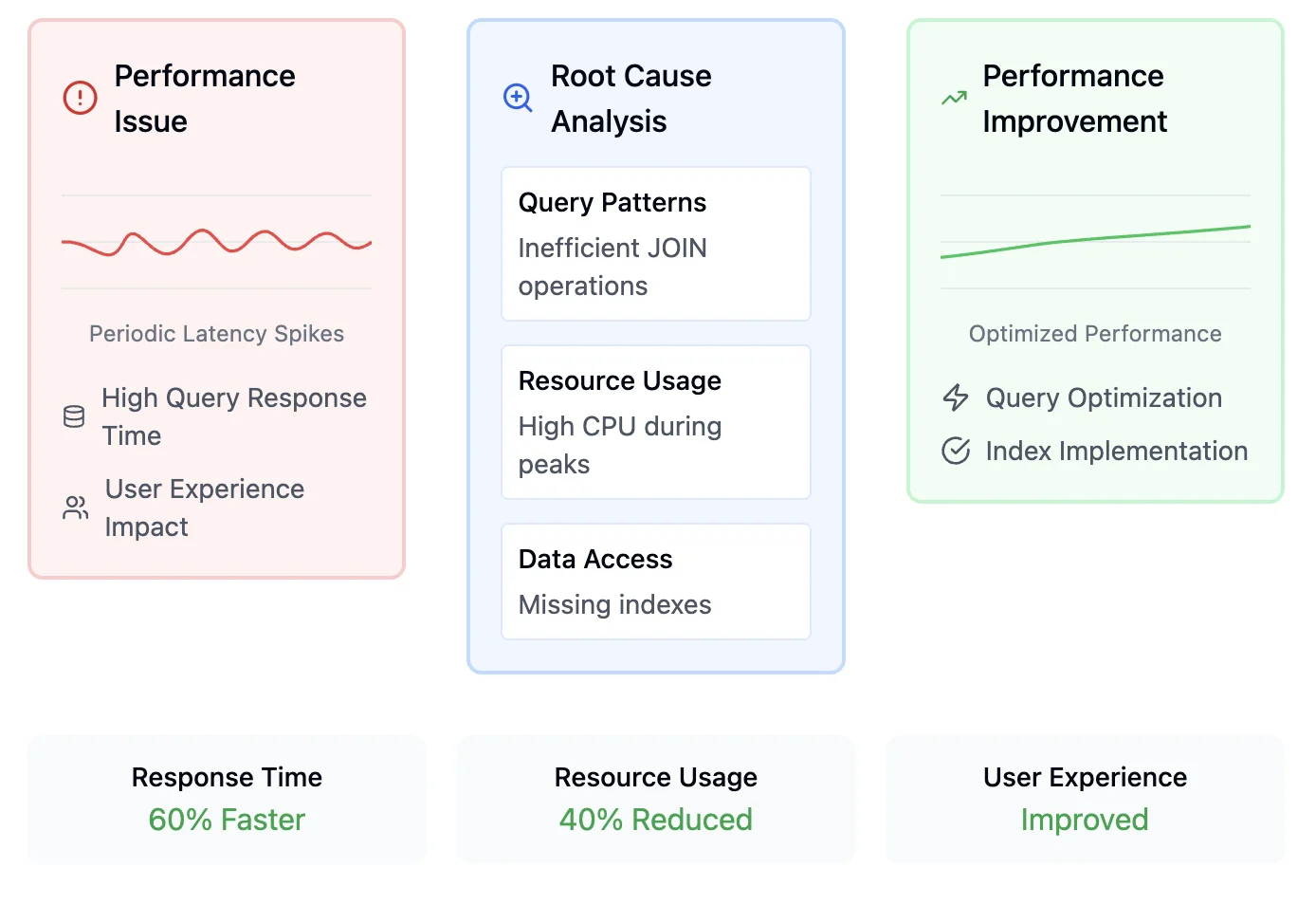
Key Drivers for Adopting Unified Observability
Organizations are rapidly adopting unified observability to manage increasingly complex IT environments. Here are the critical factors driving this adoption:
- Digital transformation: The shift to cloud and microservices demands comprehensive visibility across hybrid environments for effective service monitoring and management.
- Customer experience: Modern digital services require zero downtime. Real-time performance monitoring helps prevent revenue loss and maintain brand reputation through proactive issue detection.
- Predictive capabilities: Advanced analytics enable early detection of potential failures, particularly crucial in high-stakes industries like finance where downtime means significant losses.
- Compliance and security: Integrated monitoring ensures adherence to frameworks like GDPR and HIPAA while providing complete visibility for vulnerability detection across infrastructure.
How Unified Observability Simplifies IT Operations
Unified observability offers several significant benefits in IT operations by consolidating data and enhancing efficiency. It integrates various tools and systems into one platform, which simplifies complex IT environments.
- Data Consolidation: A unified dashboard replaces multiple monitoring tools, providing instant access to network, server, and application data.
- Smart Detection: AI-powered anomaly detection automatically identifies issues and pinpoints root causes across the infrastructure, reducing diagnostic time.
- Rapid Response: Consolidated metrics, logs, and traces enable teams to quickly troubleshoot and resolve outages through automated alerts and insights.
- Intelligent Planning: Performance trend analysis helps predict resource needs and optimize infrastructure costs proactively.
Implementing Unified Observability: Best Practices
Implementing unified observability needs strategic planning and execution to achieve any meaningful insights. By following these best practices, teams can ensure the effective monitoring and troubleshooting of complex systems.
- Defining clear observability goals and metrics: Start by identifying the most important aspects of the system to monitor. Set measurable goals, such as reducing downtime or improving response times. Monitoring the uptime of critical services and using metrics such as latency, error rates, and throughput will help in measuring success and achieving high availability.
- Selecting the right tools and integrations for the environment: Choose tools that suit the system's architecture and support its existing platforms. Ensure that the selected tools capture and visualize relevant telemetry data and integrate seamlessly with the existing infrastructure.
- Establishing data collection and analysis processes: Consistent data collection from multiple sources is vital for a complete view of system performance. Define how logs, traces, and metrics will be gathered from various services to ensure comprehensive visibility across the application stack.
- Training teams on new observability practices and tools: Ensure that team members are well-versed with observability tools and can interpret data effectively. Regular workshops and hands-on training help teams understand dashboards, alerts, and metrics, enabling them to monitor key performance indicators specific to their architecture.
The Role of AI and Machine Learning in Unified Observability
AI and machine learning have changed the field of observability by automating the detection and resolution of issues within complex systems. These technologies help streamline monitoring processes and provide deeper insights into system performance. Several key areas illustrate their impact:
Automated Pattern Recognition and Anomaly Detection
AI-driven tools analyze huge amounts of telemetry data, like logs, metrics, and traces, to recognize patterns and identify anomalies. Instead of relying solely on manual thresholds, these tools learn from historical data and flag unusual behaviour. For example, in a cloud-native environment, AI can detect an unexpected spike in API response times, immediately alerting teams to potential performance bottlenecks.
Predictive Analytics for Proactive Issue Prevention
Machine learning models can predict future system issues by reviewing trends and patterns in historical data. This predictive capability helps teams to take proactive measures to prevent downtime or degraded performance. An e-commerce platform, for example, can use predictive analytics to forecast traffic surges during seasonal sales and automatically allocate more resources to prevent service slowdowns.
Intelligent Alert Correlation and Noise Reduction
Unified observability platforms often receive numerous alerts, many of which may be unrelated or redundant. AI helps correlate these alerts by grouping related issues and filtering out unnecessary noise. For example, in a microservices architecture, AI can correlate alerts from different services impacted by a shared dependency, reducing the time it takes to identify and resolve the root cause.
Continuous Learning and Improvement of Observability Insights
AI models continuously improve with time as more data is collected and analyzed. This helps to provide more accurate insights, as the system learns from past incidents and refines its predictions. A monitoring tool for a web application, for example, can continuously improve its ability to detect performance degradation by learning from previous instances of downtime.
Overcoming Challenges in Unified Observability Adoption
Implementing unified observability can present some challenges which are discussed below:
- Data volume and variety: Handling the sheer amount and diversity of data requires robust infrastructure and efficient processing.
- Tool integration: Ensuring seamless integration between existing tools and new observability platforms can be complex.
- Data privacy and security: Centralizing monitoring data raises concerns about access control and data protection.
- Cultural resistance: Shifting to a unified observability approach may require changes in team structures and workflows.
To overcome these challenges:
- Data Volume Management: Platforms must efficiently handle diverse data sources (logs, metrics, traces) to prevent bottlenecks and optimize storage costs. Implement effective data ingestion and retention strategies.
- Tool Integration: Consolidating multiple observability tools requires careful planning. Use standardized APIs and connectors to streamline integration of various monitoring solutions.
- Data Security: Protect sensitive operational data through access controls, encryption, and regular audits. Ensure compliance with regulations like GDPR and CCPA.
- Cultural Adoption: Foster a data-driven culture through regular training and workshops. Encourage teams to actively use observability data for decision-making and problem-solving.
Unified Observability in Action: Real-World Use Cases
Unified observability offers substantial advantages across different industries by providing integrated metrics, logs, and traces. Here’s a closer look at its impact:

Unified Observability in E-commerce
- Challenge: Managing customer experience during high-traffic periods, such as sales events.
- Solution: Real-time monitoring of user interactions, transaction success, and system health.
- Result: Achieved a reduction in cart abandonment rates, enhancing site reliability and customer satisfaction.
Unified Observability in Financial Services
- Challenge: Adhering to rigorous regulatory standards while ensuring robust system performance.
- Solution: Integration of comprehensive logging, auditing, and performance monitoring.
- Result: Reduced compliance reporting time and decreased security incidents, ensuring both regulatory compliance and security.
Unified Observability in Healthcare
- Challenge: Maintaining continuous availability of crucial patient care systems.
- Solution: Utilization of predictive analytics for monitoring system health and implementing automated incident responses.
- Result: Achieved 99.99% uptime for critical services and expedited issue resolution, significantly improving patient care reliability.
How SigNoz Enables Unified Observability
SigNoz is an open-source observability platform designed to provide unified observability by integrating logs, metrics, and traces into a single cohesive solution with anomaly detection capabalities. This approach enables organizations to monitor their applications and infrastructure effectively, facilitating real-time insights and proactive issue resolution.
Unified Data Collection
SigNoz utilizes OpenTelemetry to standardize the collection of telemetry data (logs, metrics, and traces) across various applications and services. This ensures consistency and facilitates easier data correlation.

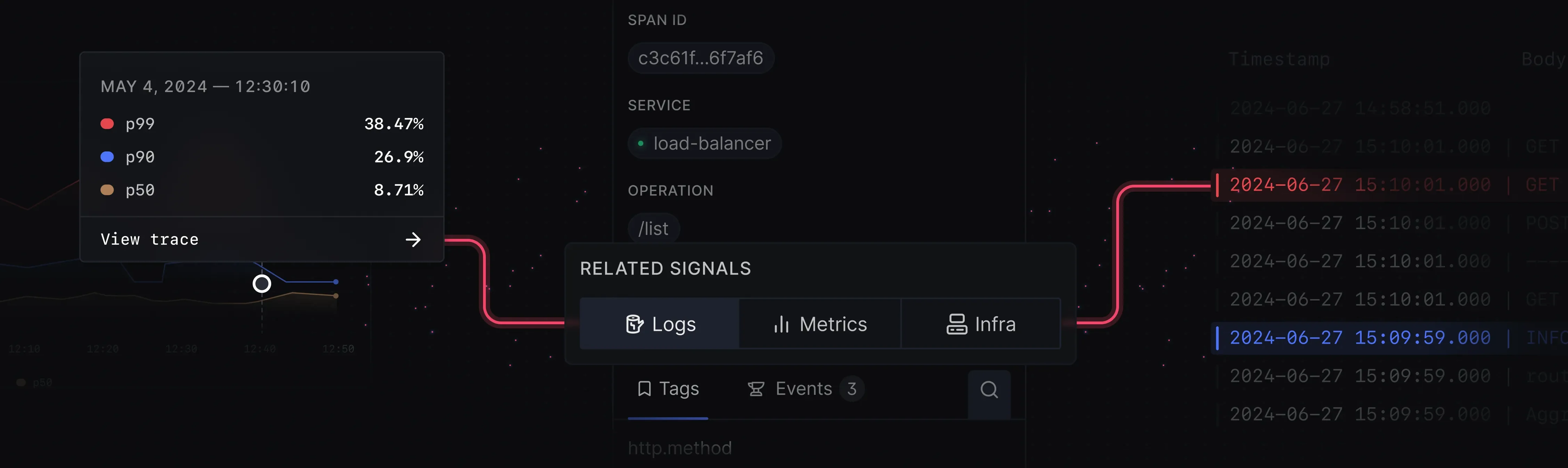
Correlated Analysis
The platform allows users to seamlessly navigate between different types of observability data. Correlating logs, metrics and traces for much richer context while debugging.
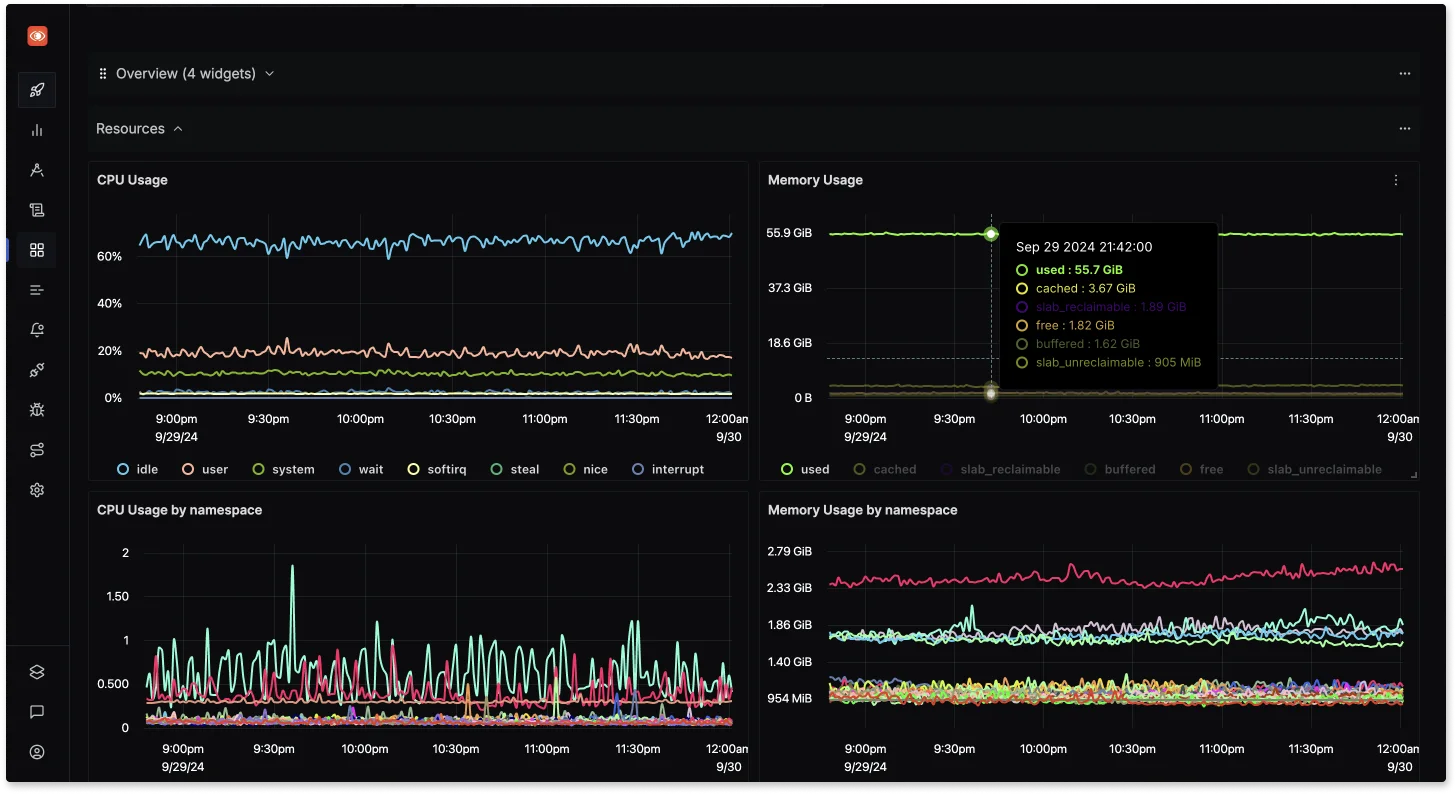
Advanced Visualization
SigNoz offers customizable dashboards that visualize performance metrics, making it easier to identify trends and anomalies. Users can create tailored views focusing on specific metrics relevant to their applications.
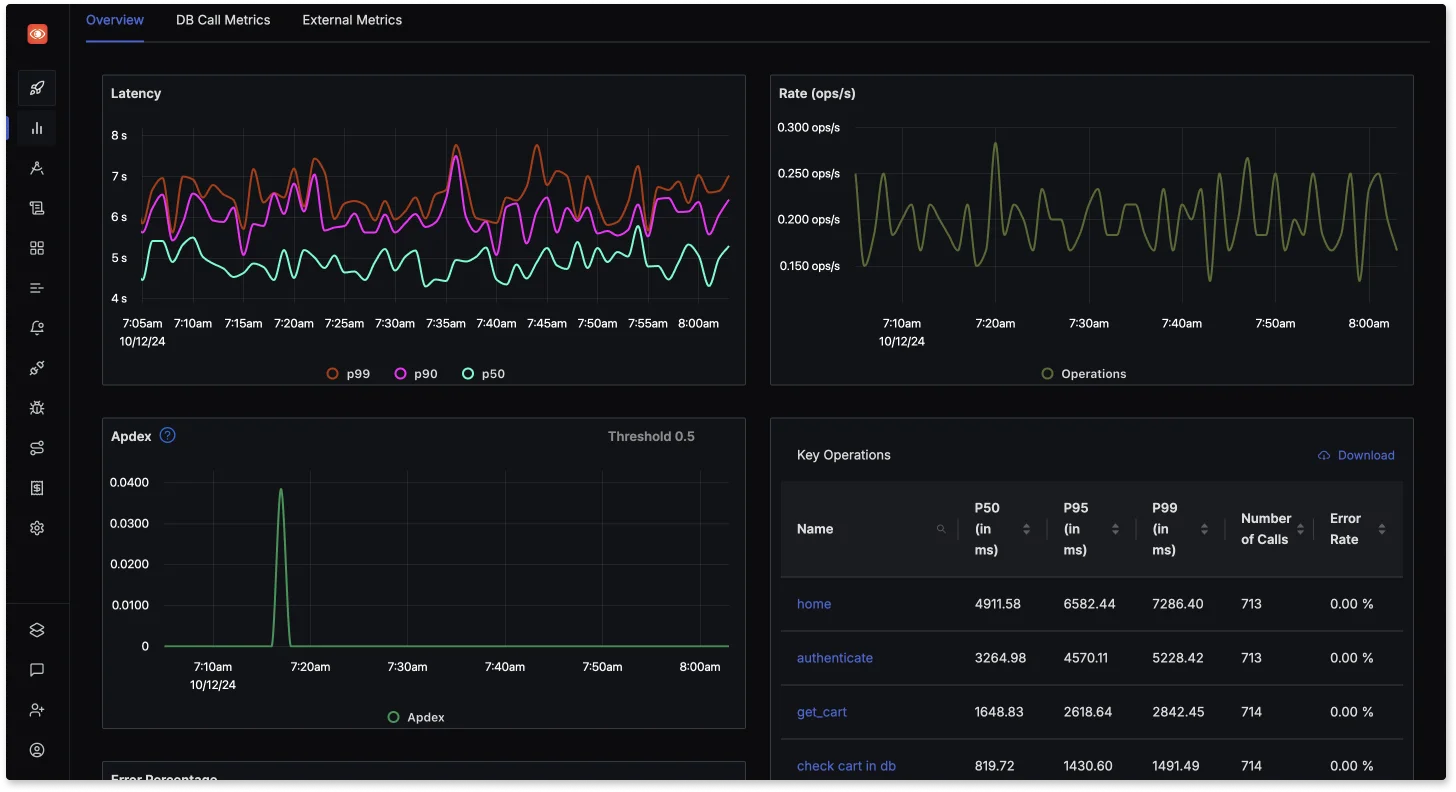
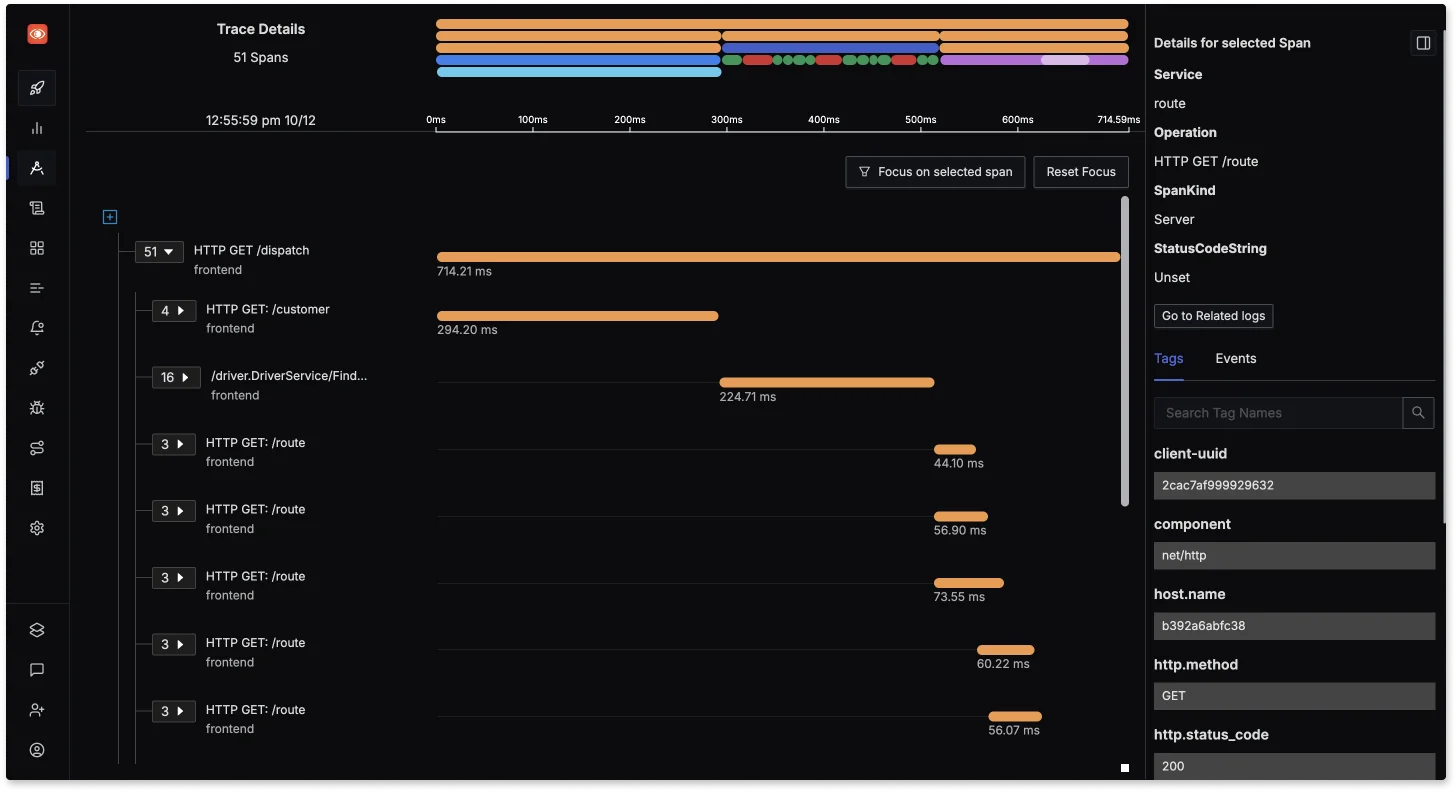
Application Performance Monitoring (APM)
With features like distributed tracing and detailed flamegraphs, SigNoz helps developers understand the flow of requests through microservices architectures, enabling them to pinpoint bottlenecks and performance issues.
Alerting System
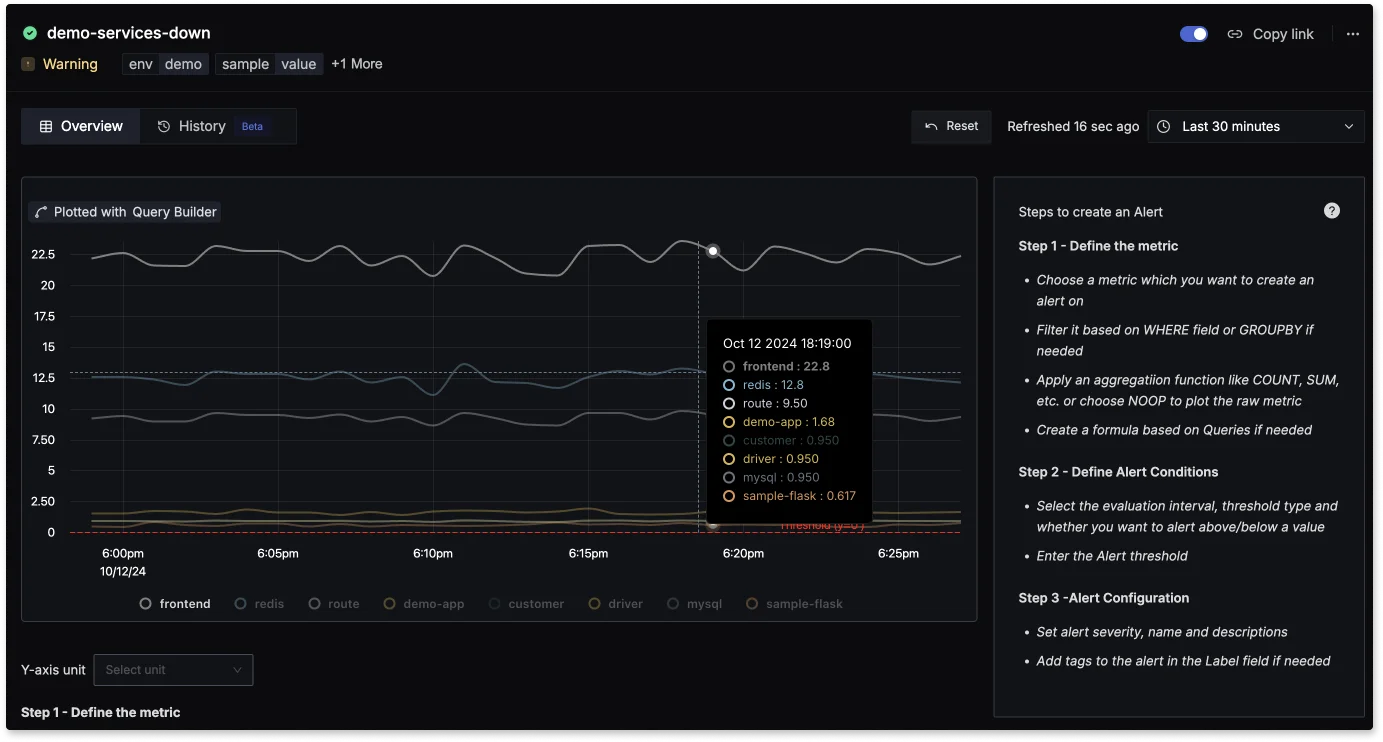
Users can set up alerts based on specific metrics or log events, allowing for proactive management of potential issues before they escalate into significant problems.
Get Started with SigNoz
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account and get 30 days of unlimited access to all features.

You can also install and self-host SigNoz yourself since it is open-source. With 19,000+ GitHub stars, open-source SigNoz is loved by developers. Find the instructions to self-host SigNoz.
Future Trends in Unified Observability
The field of unified observability is rapidly evolving with key trends:
- AIOps Integration: AIOps uses AI to automate tasks and improve decision-making. It analyzes data to detect anomalies and predict issues, speeding up responses and reducing manual effort. For example, AIOps can identify performance problems before they affect users.
- Business Metrics Correlation: Linking IT performance to business outcomes helps organizations see the impact on revenue and customer satisfaction. For instance, monitoring how slow response times affect conversion rates allows for targeted performance enhancements.
- Extended User Experience Monitoring: Advanced monitoring now tracks detailed user behavior, such as click paths and session durations. This helps identify pain points and optimize user journeys. Analyzing this data reveals where users experience issues, guiding improvements.
- Edge Computing Observability: Observability is expanding to include edge devices and IoT. Monitoring these devices ensures they perform reliably within the broader system. This is crucial for applications that depend on real-time data from edge environments.
- Observability-as-Code: Integrating observability into infrastructure-as-code (IaC) practices ensures consistent and automated monitoring setups. Defining observability in code simplifies deployment and reduces manual errors.
Key Takeaways
- Unified observability provides a holistic view of your IT ecosystem, integrating metrics, logs, and traces for a complete system view.
- It enables proactive issue detection and faster problem resolution by leveraging AI and machine learning for real-time anomaly detection and responses.
- AI and ML play crucial roles in modern observability platforms, improving decision-making and automating issue identification.
- Unified observability helps break down silos between development, operations, and security teams, improving collaboration.
- Implementing unified observability requires careful planning and cultural shifts, along with strong problem-solving and DevOps practices.
- It enhances system performance by continuously identifying bottlenecks and inefficiencies, leading to optimized resource allocation.
- The future of observability is closely tied to AIOps and business intelligence, driving smarter insights and automation.
- Predictive analytics in observability helps prevent issues before they impact users, ensuring smoother IT operations.
FAQs
What's the difference between monitoring and observability?
Monitoring focuses on tracking predefined metrics and alerts. At the same time, observability provides deeper insights into system behavior and enables asking new questions about your IT environment without deploying new instrumentation.
How does unified observability improve IT security?
Unified observability enhances security by providing a comprehensive view of your IT landscape, enabling faster detection of anomalies, improved threat-hunting capabilities, and better correlation of security events with system performance data.
Can unified observability work in hybrid and multi-cloud environments?
Yes, unified observability platforms are designed to work across diverse environments, including on-premises, public cloud, and multi-cloud setups. They provide a consistent view and analysis capabilities regardless of where your applications and infrastructure are hosted.
What skills are needed to implement and manage unified observability?
Key skills include:
- Understanding of modern IT architectures and cloud technologies
- Familiarity with data analysis and visualization techniques
- Knowledge of AI and ML concepts
- Experience with DevOps and SRE practices
- Strong problem-solving and critical-thinking abilities
Continuous learning is essential as the field of unified observability rapidly evolves.
How does unified observability enhance incident response?
Unified observability enables faster incident response by providing real-time insights into system anomalies, allowing teams to quickly identify the root cause of issues, reduce downtime, and prevent recurrence.
What role do AI and ML play in unified observability?
AI and ML automate anomaly detection, predictive analytics, and root-cause analysis, enabling teams to proactively address issues and optimize system performance before they impact the end user.
Is unified observability suitable for small organizations?
Yes, unified observability can benefit organizations of all sizes. Many platforms offer scalable solutions that can be tailored to fit the needs of smaller organizations while still providing comprehensive visibility and analysis of system performance and security.

